本文是《WeChat Bot系列》系列的一部分:
- 能理解聊天记录的微信机器人
- 能理解聊天记录的微信机器人(二)(本文)
- 能理解聊天记录的微信机器人(三)
根据(一)的一些思路,今天把一些简单的统计功能给做了出来,部署在了个人微信号上。主要的功能是:
- 如果群里有人发
/tagcloud,就统计群里最近500条消息的标签云,然后发上去 - 如果群里有人发
/mytag,就统计这个人最近500条消息的标签云,然后发上去 - 如果群里有人发
/activity,就统计这个群最近一天的发言情况(每小时有多少条消息,每个人讲多少话等等),把图片发上去
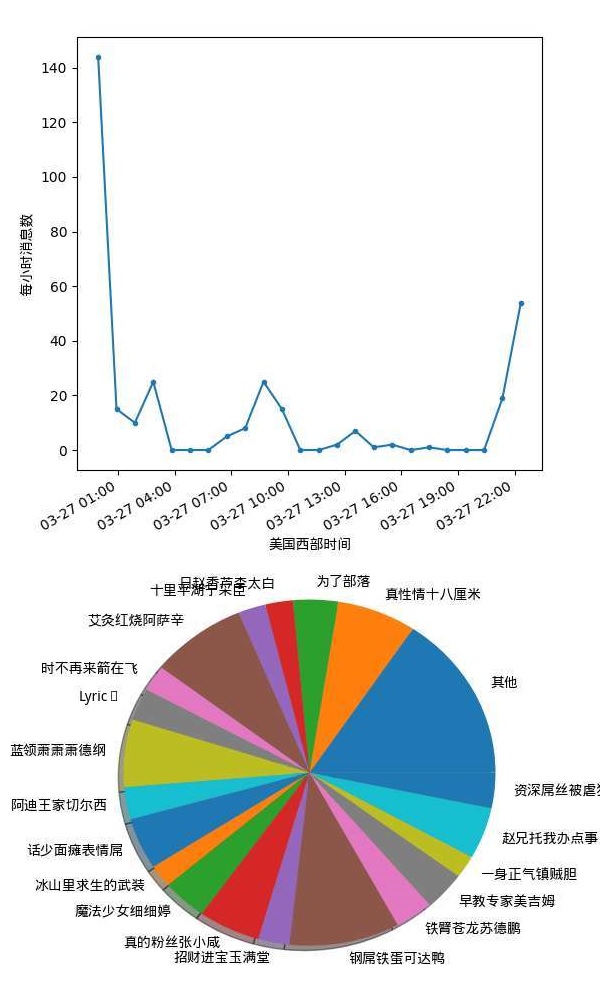
大家都蛮感兴趣的,在我的个人号上部署了两个小时,收到了400多个请求。也来了不少黑客开始玩这个系统,什么大鸭蛋,鸭大蛋都出来了。。



也支持一些简单的统计了:
此外,部署一周以后,花了几个小时的时间做了一些改动,有意思的部分主要有:
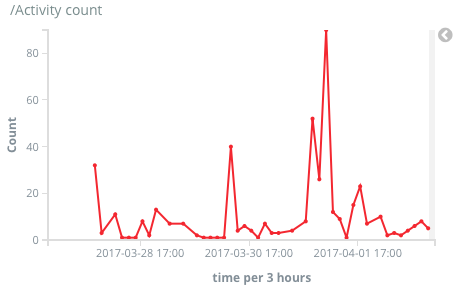
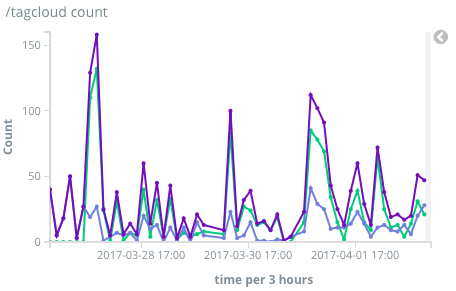
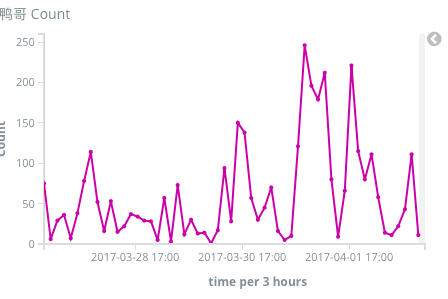
- 和ElasticSearch和Kibana连了起来,现在有了实时监控和可视化了。能看到每小时平均有多少次自动回复,多少次看群里话唠,多少次看标签云。令我意外的是已经过去一周了,可是大家的热情仍然没有消退。尤其是最简单的自动回复功能,你提到"鸭哥"机器人就会自动回复"嘎?"。这么简单的功能我以为用户会玩玩就腻了。但数据显示,直到今天还有每小时30多次的峰值调戏量。甚至有个群一晚上刷了几百个鸭哥。。真是不能随便猜用户喜欢什么东西啊。。
- 第二个改动就是把标签云的算法从TF换成了TF-IDF。TF (Term-Frequency)就是最简单的数词频,这是最简单可靠的算标签云的方法,但有一个缺陷,如果没有对一些无意义的虚词做特殊处理的话,会很容易出现一些巨大但没啥意义的词。比如这个例子,"这个","就是","可以"等等。占据了大量的空间,但没啥信息量。

而IDF(Inverse-Document Frequency)则可以解决这个问题。它基本上代表了每个词的信息量。IDF的基本思想是,如果一个词在好多群里面都有出现(比如"的"),那么就对这个词施加惩罚,让它的权重变小。如果这个词只在几个群里面出现(比如"社会主义"),那就让它变大。这样就能保证,面积最大的几个词不仅是大家经常说的,而且是最有信息量的。经过算法的这个更改以后,我们对同一个群计算标签云,结果就变成了这样:

这个群最有特色的几个词一下就出来了。
- 此外,我还试着把标点符号也加入到了计算里面,结果很有意思。大多数的群的标签云里面都是没什么标点符号的。原因很简单。第一,聊天的时候以短句为主,后面本来就很少加标点,TF不高。第二所有群基本上用标点的频率都差不多,所以标点的IDF也差不多。因此不会有标点特别大的情况出现。但我看到了两个群有很大的标点出现。

上面这个图是科大的AI群。因为里面经常进行一些大段的深入的讨论,所以逗号,句号和顿号都非常明显。而下面这个群,则是因为在聊买房,贷款,所以出现了百分号%。又因为这个符号在其他群里都没有出现,所以IDF巨大。一下就抢占了很大的空间。这也是为什么里面出现了房子,地主婆等关键字的原因。。

所以在某种程度上,这个机器人已经可以理解大家说话的内容了。比如可以区分内容中独特的部分。这对于分类,聚类等等进一步的应用都是非常有帮助的。如果你有什么有意思的应用,也可以在评论中提出来,我们来帮你实现。 代码也已经开源 [github]。此外,你也可以了解斗图功能的开发和自动转发功能。