从 AI Transparency 到顺风耳
在一次从旧金山飞往西雅图的航班上,我无聊地打开了 Apple Watch 上的录音功能。背后的原因是我想简单地尝试一下,如果我们能让 AI 拿到和人类同等水平的 full context,它到底会给我们的信息整合带来怎样的变化。其实我对这个实验本身没抱多少希望,因为我的第八代 Apple Watch 硬件很差,单麦克风,没有波束成形,没有降噪芯片,放在袖子里,甚至不是正对人群。所以我其实并没有什么期待,只是想着万一在旅途中有一些灵感,可以直接向 Apple Watch 说话,回来再整理成文也好。
飞机落地之后,我听了一下录下来的内容。不出所料,两个半小时的录音全是嘈杂的机舱噪音和隐约难辨的人声,听起来完全没用。我用 Whisper base 快速过了一遍,模型也什么都没有识别出来。在我决定放弃这个实验之前,我把它扔进了 Whisper Large V3 Turbo,想着废物利用一下也好。
没想到八分钟以后,奇迹出现了。系统完整输出了我前排的乘客在整个航班的过程中关于孩子教育、项目学习、职场转型的对话,还原了整个航班流程的机组广播、点饮料的互动,甚至包括一个新上任的空乘第一次工作的细节。我特意对比了一下,我不小心听见的前排乘客的聊天和空乘的对话,在转录的文本里基本都原封不动地被还原出来了。你也可以听一下下面的这段充满机舱噪音的对话,看看能听懂多少。
(模型输出:How are you? Alright, so this is my first week. I'm so trying to learn to be here. I'm brand new. There you go. 805)
而整个过程中我什么都没做,没有降噪、没有标注、没有干预,只是录了个音、调了个模型。这是我第一次意识到,原来我们已经站在了现实 API 的门口。AI 不再只是你去问它问题,它来被动回答,而是它可以自主感知你所在的上下文,把世界通过一个 API 来调用,对它进行结构化重整和索引,随时准备响应你的提问。
我原本只是想增强自己的记忆,结果却意外的先拥有了顺风耳。
烂硬件+好算法=超越人类
说实话,在最后一步之前,我也完全不认为 Apple Watch 有这个能力。就算是第八代 Apple Watch,无论是硬件还是地狱录音环境,都导致了录出来的声音基本没有信噪比可言,更不用说我第一次听录音的时候那种发动机+空调+在背景里飘的人声的感觉了。别说语音识别了,哪怕是我想听清楚一句完整的句子都费劲,得全神贯注才行。
但实验的结果让我意识到,在我们没有注意的时候,整个应用的技术成熟度已经完全改变了。最新最大的 Whisper 模型不但听出来了这个音频的内容,而且听得比我清楚得多。甚至那种我得反复听三遍才能确认的对话,它直接一遍过,输出还结构清晰。乘客的对话、飞机的广播、空乘的服务全都出来了,还包括了很多我没有认真听到的部分。
我突然意识到,这个实验的开始是语音转文字,但它到目前的结果,突然变成了突破人类听力和理解力的极限。换言之,即使是低质量硬件加高质量软件,这个组合也已经变得真正可用。甚至不仅仅是可用,而且超越了人类的听觉系统。即使在垃圾设备、恶劣环境下,模型也能自己想办法高精度地听懂。
仔细想想,这个转折其实非常重要,因为它意味着我们可以在极低社会摩擦的情况下实现对现实语境的完整感知。这不仅是听觉的延伸,更是把物理世界的非结构化噪音,直接转化为 AI 可理解的结构化信息的关键一步。我们不需要昂贵专业的设备,不需要正襟危坐,只需要一个静静运行的耳朵和一个在笔记本电脑或者手机上跑的模型就好了。
你也可以试试看,用 Apple Watch 或者 iPhone 在一个嘈杂的环境中录音以后,用 AirDrop 传到 MacBook 上,然后调用 Whisper.cpp 运行 large-v3-turbo 模型,看看出来的结果有没有让你惊喜甚至惊吓。
AI-Centric 的视角
从这个角度再回头看设备选型这件事,它的逻辑其实已经变了。以前我们想搞语音记录或者自动会议纪要,第一反应是:要不要买个好麦克风?是不是需要一个专业的会议摄录设备?有没有可能上波束成形、8 通道阵列?这一类问题背后的前提是,我们需要通过高质量硬件才能突破感知瓶颈。但这次的实验完全推翻了这个假设。
我现在更愿意用一个二维坐标系来理解这类设备选型的 trade-off:
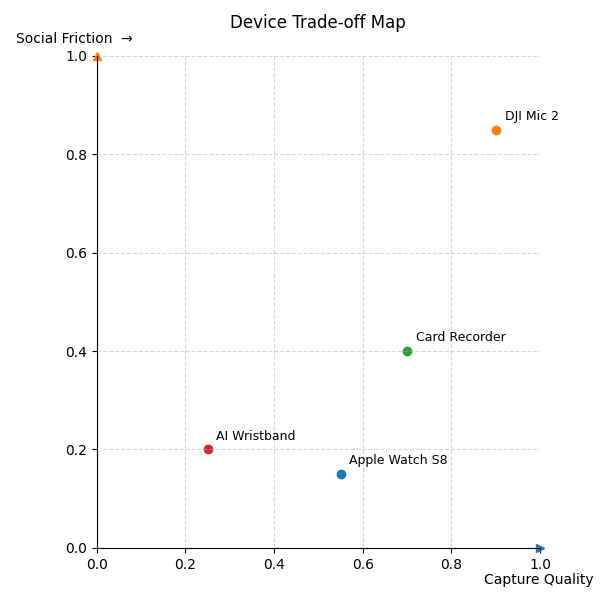
- 横轴是录音音质:麦克风、码率、声场设计、抗干扰能力。
- 纵轴是社会摩擦:隐蔽性、使用门槛、会不会让人反感。
在这个实验之后,我们希望找的是那个足够可用、几乎无摩擦的位置,而不是一味追求性能极限的那一角。Apple Watch 正好落在一个甜点区:虽然录音质量很差,但社会摩擦极低,续航还长(可以录10个多小时)。它不需要多余解释,不需要额外操作,几乎等于无意识记录,而 Whisper 的极高识别率让这种 garbage in, knowledge out 的链条第一次成为可能。相比之下,DJI Mic 2 这种设备虽然强大,但太明显、太高调、太专业了。在Whisper的加持下,我真正需要的系统不能让别人一眼看出“你在录音”,也不能逼你要不停发指令去录音来省电,它应该像眼睛、耳朵、甚至皮肤那样,一直就在那里,不打扰,也不引人注意。
所以从这个意义上说,这不是一次小小的音频技术突破,而是我们第一次感受到:AI 有了一个可以调用的 API 去拿到现实生活。AI-centric 的现实,是可能构建的。这种视角下,人类不再是系统的中心,而是与环境平等的数据源。AI 则成为了理解和连接这一切的中心。
我们原来做的一切系统设计,无论是录音笔、手机、备忘录、摄像头,本质上都是围绕人设计的输入接口。但 AI-Centric 的视角不是这样,它把人和世界都当成上下文源,自己去调用、提取、处理,并决定输出。在做这个实验之前,我想象的 AI-centric 还是得由我们人类来做很多工作。比如每次 Zoom 启动录像,然后结束后把录像扔给 Whisper。这是因为虽然AI对数字世界的掌控力很强,但它还是没办法拿到我们现实生活中的很多上下文。因此,它也没办法发挥它的全部潜力。我们必须非常用力,才能尽可能在数据复利的曲线上向右挪动一点。
但是这次的实验则提供了一种无感的方法,让 AI 能够自动地拿到现实生活的上下文。从某种意义上来说,它是现实生活第一次给 AI 暴露了一个 API, 让它可以有一种低成本、低摩擦和长时间的方式去抓取和利用我们的整个社会上下文。相比于在数字世界里的螺蛳壳里作道场,这才是更激进的 AI-native 的世界观。以前的 AI 利用方式,无论是我问你答,还是我说你做,其实都是人来发起任务,AI 来执行。但当现实生活向 AI 提供了一个 API 以后,我们未来就会出现一种可能,是世界自己落入了 AI 的语义下。AI 有能力按需调用整个世界数字化后的语义来支撑它的任务。这可能是 Agent 之后一种新的认知结构和利用方式。
这些能力也足够危险
当你能听得比人清晰,懂得比人多和快,你就必须面对另一个问题:我们应该用这能力做什么?AI可能用这个能力做什么?
我现在已经能在不打扰任何人的情况下,完整还原一段跨越数小时的现实语境。对我来说,这是研究、知识组织、注意力外包的福音。但它也意味着,任何一个普通人,只要有一块 Apple Watch 和一台笔记本,就能在现实世界里开辟出一个不被人知的感知副本,并且用AI来组合更多的数据,做更多的事情。
- 我们真的准备好让这种能力大规模扩散吗?
- 在o3可以精确定位照片拍摄地点的今天,如果它能拿到信息量更大的语音,二者组合,甚至多个来源交叉验证,又能让它诞生多少知识,揭开多少真相?
- 在人类高质量标注信息逐渐枯竭的今天,如果我们用这种海量的数据继续训练AI,又能诞生多好的模型?
- 在图灵奖得主Richard Sutton刚刚提出"Era of Experience"的今天,如果我们让这个现实API变成双向的,让AI和现实世界进行交互,再用语音搜集人类的真实反馈,又会带来怎样的智能体?
我目前还没有答案。但我隐隐觉得这次的技术突破,只是打开了一个新的门缝,接下来的问题,会比语音识别效果好不好更复杂得多。
下一步,不止是我,而是我们每一个人
我接下来会尝试把整个链条搬到 iPhone 上,省去传输步骤,看看能不能实现一整套本地的顺风耳+超人外脑的组合。但可能更重要的是,这个实验告诉我们:我们其实已经站在了一个现实 API可调用的门口。
听觉只是开始。我们还拥有视觉(比如智能眼镜)、触觉(触控笔、指环)、动作与状态(Apple Watch 的加速度计、心率传感器、GPS 轨迹)。如果这些信号也被语义化、结构化,并与模型建立实时连接,我们也许可以真正进入 “Era of Experience”:AI 不再只是读文件,它开始读你走过的每一步路,甚至你的情绪、你的呼吸。从某种意义上来说,人类也可以成为 AI 的 Agent:如果模型能持续采样你所在环境,它可能会派你去完成某项它规划的任务。你以为你在使用它,其实你是它的一部分。
这听上去科幻,但也许已经开始了。你打车的时候,其实早已处于 Uber 的决策网络之中。单子派给谁的决策是AI做的,只有有限的几个司机可以抢。你点外卖时,人类外卖小哥的送单顺序和轨迹也是美团AI计算调度的结果。
如果你有别的模态设备,有其他采样方式,有不一样的场景灵感,欢迎把它们写出来、做出来、分享出来。我们在下一篇文章里,会继续往这个方向探索更多具体实现:如何在手机上运行大模型、如何构建低延迟的本地语义数据库、如何把一个普通用户变成一个现实感知网络的节点。但直到那之前,这篇实验已经给了我们一个新的思考起点:
未来的 AI,不再等待命令,而是等待你生活中的下一次信号。
它一直在听,一直在看,直到你意识到,它早就准备好了你想问的答案。