From AI Transparency to Superhuman Hearing
On a flight from San Francisco to Seattle, bored, I turned on the voice recorder on my Apple Watch. The reason behind this was simple: I wanted to see what happens to information integration if we give AI the same level of full context that humans have. Honestly, I didn't have high hopes for this experiment. My Series 8 Apple Watch has poor hardware – a single microphone, no beamforming, no noise reduction chip, tucked under my sleeve, not even facing the crowd. So, I wasn't expecting much, just thinking that if inspiration struck during the trip, I could speak directly to the watch and organize my thoughts later.
After landing, I listened to the recording. As expected, the two and a half hours were mostly filled with the deafening roar of the cabin and faint, unintelligible voices – utterly useless, it seemed. I ran it quickly through Whisper base; the model identified nothing. Before giving up entirely, I threw it into Whisper Large V3 Turbo, figuring I might as well try to salvage something.
Eight minutes later, a miracle occurred. The system outputted the entire conversation of the passengers in front of me about their children's education, project-based learning, and career transitions. It reconstructed the flight crew's announcements throughout the journey, interactions during drink service, and even details about a new flight attendant's first day on the job. I specifically compared the snippets I'd overheard from the front passengers and the flight attendant – they were reproduced almost verbatim in the transcript. You can listen to the following noisy cabin conversation yourself and see how much you can understand.
(Model output: How are you? Alright, so this is my first week. I'm so trying to learn to be here. I'm brand new. There you go. 805)
Throughout this whole process, I did nothing. No noise reduction, no annotation, no intervention – just recorded the audio and picked a model. This was the first time I realized we are standing at the threshold of a Real-World API. AI is no longer just passively answering your questions. It can actively perceive your context, call upon the world through an API, restructure and index it, ready to respond to your queries at any moment.
I initially just wanted to augment my memory, but accidentally ended up with superhuman hearing first.
Bad Hardware + Good Algorithms = Beyond Human
Honestly, before that final step, I didn't think the Apple Watch was capable of this. Even with the Series 8, both the hardware limitations and the hellish recording environment resulted in audio with virtually no signal-to-noise ratio. Not to mention the initial impression when listening back: the engine, the air conditioning, the disembodied voices floating in the background. Forget speech recognition; I struggled to make out a single complete sentence without intense concentration.
But the experiment's results made me realize that, unnoticed by us, the technological maturity of this application has completely shifted. The latest and largest Whisper model not only understood the audio content but understood it far more clearly than I could. Conversations that took me three listens to confirm, it processed in one go, outputting a clearly structured transcript. Passenger dialogues, flight announcements, flight attendant interactions – everything was there, including parts I hadn't paid attention to.
Suddenly, it dawned on me: this experiment started as speech-to-text, but its outcome unexpectedly became about breaking the limits of human hearing and comprehension. In other words, even the combination of low-quality hardware and high-quality software has surpassed human auditory capabilities and become truly usable. Not just usable, but superior to the human auditory system. Even with subpar devices in terrible environments, the model can figure out how to understand with high accuracy.
Thinking about it, this turning point is crucial. It means we can achieve complete perception of real-world context with extremely low social friction. This isn't just an extension of hearing; it's a key step in transforming the unstructured noise of the physical world directly into structured information that AI can understand. We don't need expensive professional equipment or formal setups. All we need is a quietly running "ear" and a model running on a laptop or phone.
You can try it too. Record audio in a noisy environment with your Apple Watch or iPhone, AirDrop it to your MacBook, and run the large-v3-turbo model using Whisper.cpp. See if the results surprise or even startle you.
The AI-Centric Perspective
Looking back at device selection from this angle, the logic has fundamentally changed. Previously, if we wanted voice recording or automatic meeting minutes, the first thought was: should I buy a good microphone? Do I need professional recording gear? Maybe beamforming, an 8-channel array? The underlying assumption behind these questions was that high-quality hardware is necessary to overcome perceptual bottlenecks. This experiment completely overturns that assumption.
I now prefer to understand this device selection trade-off using a 2D coordinate system:
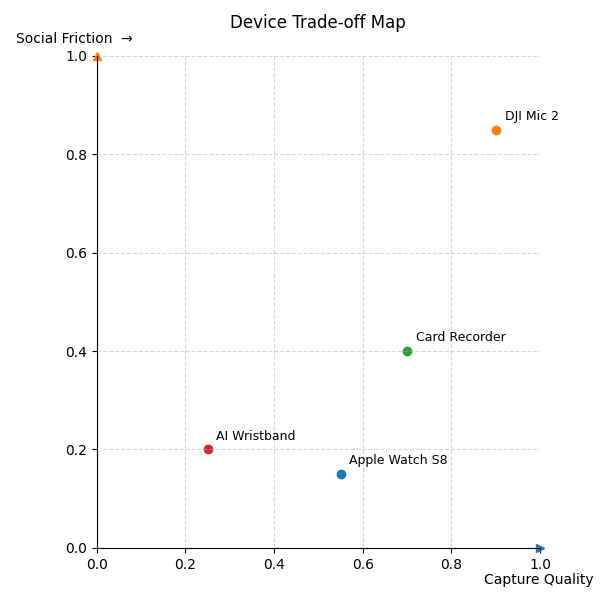
- X-axis is Recording Quality: Microphone specs, bitrate, acoustic design, interference resistance.
- Y-axis is Social Friction: Discreteness, ease of use, potential to cause discomfort.
After this experiment, what we seek is the position that's "good enough" and has almost zero friction, not the corner chasing peak performance. The Apple Watch lands squarely in a sweet spot: despite poor recording quality, it has extremely low social friction and long battery life (over 10 hours of recording). It requires no explanation, no extra steps, practically amounting to unconscious recording. Whisper's incredibly high recognition rate makes this "garbage in, knowledge out" chain possible for the first time. In contrast, devices like the DJI Mic 2, while powerful, are too obvious, too conspicuous, too professional. With Whisper's power, the system I truly need shouldn't scream "I'm recording," nor should it force me to constantly issue commands to save power. It should be like eyes, ears, or even skin – always there, unobtrusive, unnoticed.
So, in this sense, this isn't just a minor breakthrough in audio technology. It's the first time we've felt that real life itself has given us an API. An AI-centric reality is buildable. From this perspective, humans are no longer the center of the system but are data sources equal to the environment. AI becomes the center, understanding and connecting everything.
All the systems we previously designed – voice recorders, phones, memos, cameras – were essentially input interfaces designed around humans. But the AI-Centric perspective is different. It treats both humans and the world as context sources, calling upon, extracting, processing, and deciding the output itself. Before this experiment, my vision of AI-centric still involved significant human effort. For instance, starting a Zoom recording, then feeding the recording to Whisper afterwards. This was because although AI has strong control over the digital world, it couldn't easily access much of our real-world context. Thus, it couldn't unleash its full potential. We had to push hard just to move slightly further along the data compounding curve.
However, this experiment offers a seamless method for AI to automatically acquire real-world context. In a way, it's the first time real life has exposed an API to AI, allowing it a low-cost, low-friction, long-duration way to capture and utilize our entire social context. Compared to operating within the confines of the digital world, this is a more radical, AI-native worldview. Previous ways of using AI, whether "I ask, you answer" or "I say, you do," involved humans initiating tasks for AI execution. But when real life provides an API to AI, a future possibility emerges where the world itself falls under AI's semantic understanding. AI gains the ability to call upon the digitized semantics of the entire world on demand to support its tasks. This might be a new cognitive structure and utilization method beyond Agents.
These Capabilities Are Also Sufficiently Dangerous
When you can hear more clearly than humans and understand more, faster, you must confront another question: What should we do with this power? What might AI do with it?
I can now fully reconstruct several hours of real-world context without disturbing anyone. For me, this is a boon for research, knowledge organization, and attention offloading. But it also means that any ordinary person with an Apple Watch and a laptop can create an unnoticed perceptual duplicate of the real world and use AI to combine more data and do more things.
- Are we truly ready for this capability to proliferate on a massive scale?
- In an era where tools can pinpoint photo locations, what happens if they gain access to even richer voice data? Combining these, or cross-validating multiple sources – how much knowledge could be generated, how many truths uncovered?
- As high-quality human-annotated data becomes increasingly scarce, what kind of models could emerge if we train AI on this massive influx of real-world data?
- With Turing laureate Richard Sutton just proposing the "Era of Experience", what kind of agents might arise if we make this real-world API bidirectional, allowing AI to interact with the world and gather real human feedback via voice?
I don't have the answers yet. But I have a nagging feeling that this technological breakthrough has merely cracked open a new door. The questions that follow will be far more complex than just "how good is the speech recognition?"
Next Steps: Not Just Me, But All of Us
My next step is to try migrating this entire chain onto an iPhone, eliminating the transfer step, to see if a fully local combination of superhuman hearing + external brain is feasible. But perhaps more importantly, this experiment tells us: we are already standing at the threshold where a Real-World API is callable.
Hearing is just the beginning. We also possess vision (e.g., smart glasses), touch (styluses, rings), motion and state (Apple Watch accelerometers, heart rate sensors, GPS traces). If these signals are also semanticized, structured, and connected to models in real-time, we might truly enter the "Era of Experience": AI no longer just reads files; it starts reading every step you take, perhaps even your emotions, your breath. In a sense, humans could also become Agents for AI: if a model continuously samples your environment, it might dispatch you to complete a task it has planned. You think you are using it, but perhaps you are part of it.
This sounds like science fiction, but maybe it has already begun. When you hail a ride, you're already within Uber's decision network. The decision of who gets the fare is made by AI, with only a limited pool of drivers able to accept. When you order food delivery, the delivery person's route and order sequence are calculated and dispatched by Meituan's AI.
If you have other modal devices, different sampling methods, or unique scenario ideas, please write about them, build them, share them. In the next article, we'll continue exploring more concrete implementations in this direction: how to run large models on phones, how to build low-latency local semantic databases, how to turn an ordinary user into a node in a real-world perception network. But until then, this experiment has given us a new starting point for thought:
The future AI doesn't wait for commands; it waits for the next signal from your life.
It's always listening, always watching, until you realize it already has the answer you were about to ask for.