精美画风背后的短板
最近,OpenAI 发布了一个新的文生图模型。网上有很多风格转换的例子,但这篇文章想讨论另一个在商业中可能更有用的应用场景:生成在幻灯片里可以直接使用的生动图表。
生动精巧的配图和可视化是让幻灯片出彩的关键。但从头做一个配图的门槛非常高,如果不是科班设计人员,审美在线同时熟悉各种专门工具,我们普通人很难做出出彩的效果。而新的GPT模型展现出了非常精细的文字控制能力,可以可靠精准地把给定的文本自然地加到图像中去。因此,如果我们可以把GPT在图像生成上精美的风格和它对文字准确的把握结合起来,也许就可以解决我们在商业应用中的一大痛点,大幅提升幻灯片的水平。
举个例子,比如我们想要画一个流程图,这个流程图如果用普通幻灯片的方式画出来,如下图所示。它有几个基本模块,各个模块之间是简单的线性关系,用箭头连接。
这种最简单的可视化,虽然比纯粹的项目列表要容易理解一些,但很难说直观到哪里去,本质上仍然是文字的罗列。然而如果我们真的想要让它变得生动的话,又必须要牵扯到很多设计方面的元素。比如在文字之外,我们也许需要加入一些图标。当图标比较丰富的时候,又要考虑结构色彩怎么让人觉得舒服。如果要求再高一些,可能会想着把它有机地融入到一个精美的视觉场景中去,让它有一定的故事性。比如,加入一些动画角色,来变得更有故事性、更亲切自然。但是很明显,上面提到的这些思路虽然非常好,但对普通人来说完全不可行。那一个自然的想法就是,GPT能不能帮助我们做出类似的东西,实现类似下图的效果呢?(剧透:这个图就是用GPT做的)

但是如果稍微试一下就会发现,虽然相比于以往的模型,GPT在文本控制方面已经有了长足的进步,但是它对于真正商业级别的应用而言,可控性还是不够高。比如我们用这样的提示词:
I want to generate a chart in the style of "Shaun the Sheep." It will essentially look like a path in the order of:
Text in mind -> Muscle instructions -> Hand movement -> Keyboard -> Text in computer/phone
In order! And there are arrows connecting each element.
我们确实可以得到正确的文本。但是,基本上所有情况下,这个图都会有各种各样的问题。如下图所示,可能是箭头不对,可能是顺序不对,有的时候甚至会出现一些吓人的artifact。


这篇文章主要就想分享一下我的经验,来介绍怎么样用四个步骤来让GPT画流程图和可视化的能力脱胎换骨,真的达到商业级别可用的程度。
四步实现商业级精准可控
用视觉撬动AI思维
在这四个步骤中,第一个可能也是最重要的原则是一图胜千言。要注意,GPT作为一种多模态LLM,不仅接受文本作为提示词,同时还可以接受一张甚至几张图片来指导它的图像生成。很多时候,模型生成的效果不好,是因为我们给它的信息不够全面。对于模型的幻觉是这样,生成图像也是这样。比如,在上面的提示词里,我们其实没有任何一个地方说在Text in the Mind和Hand movement之间没有连接。因此它把这个连接画出来也是一件无可厚非的事情。
当然,我们可以解释说这只是因为模型太笨,如果模型足够聪明的话,不会犯这样的错误。这确实是这样。但是一方面,模型总是有它的能力边界,总是有它不够聪明的场景。另一方面,我们其实有一种简单的方法来避免这种误解。这就是我们要应用视觉优先的原则,不要只用文字来向GPT描述我们的意图,而要把图片本身作为提示词的核心内容。这个过程其实可以很简单。比如我们可以直接让Cursor画一个HTML,把上面所说的五个环节给可视化出来(就是最上面的那个方框箭头可视化)。接着我们把这个网页的截图作为提示词一部分发送给GPT,它很容易就可以生成正确的图像。
这里的关键在于,图像携带的信息量比文字要多很多。比如,Text in the Mind和Hand movement之间没有连接这件事情,对于文字描述来说是有歧义的。但如果我们把这个截图给GPT的话,它是没有歧义的——这个图像明确地表示了这两个元素之间没有任何箭头。因此,我们用图像作为提示词,本质上是帮图像生成的模型节约了脑力,用对它而言直观生动的方式,澄清了很多可能的误解和歧义。而这个澄清的过程甚至不需要我们自己去做,只要让文本生成文本的AI、聪明AI画个图出来就可以了。
从另一个角度来说,这其实恰恰是我们为什么要做可视化的原因。因为人类对图像的理解能力比对文字要强很多,觉得图像更直观更省脑力。这个观察似乎对AI也成立。所以如果我们用(即使很简单的)图像来跟AI沟通创作意图的话,效果也会好很多。
在经过了这样的图像+文字混合提示以后,我们可以得到这样的图像:
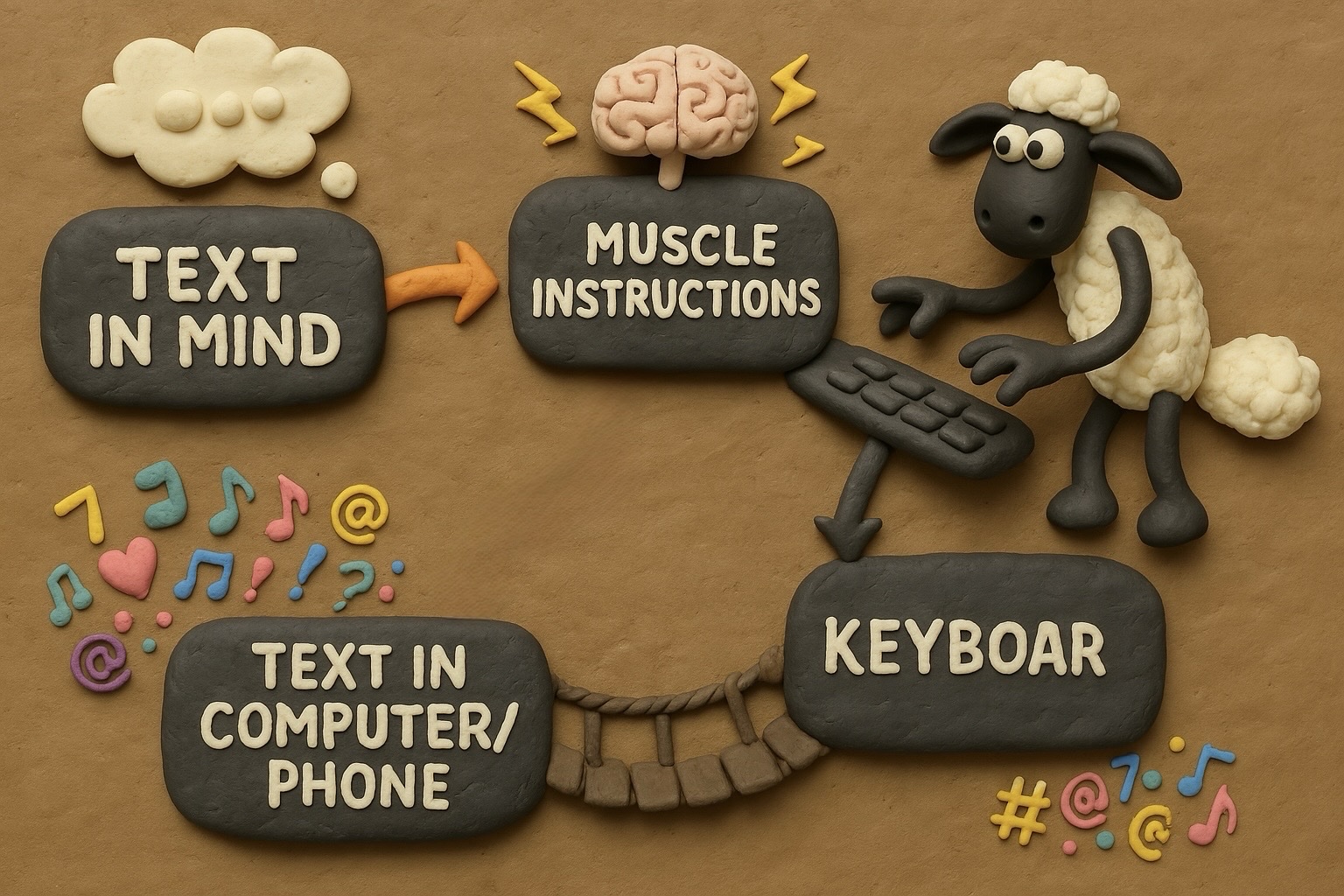
用遮罩实现迭代式生成
在上一个例子里,我们可以看到,其实生成的图像还是有一些小瑕疵的,比如右下角的“Keyboard”少了一个字母。但如果我们用同样的prompt重新生成的话,就等于彻底返工,浪费了之前的工作,修正的成功率也不高。这种情况在ComfyUI和MidJourney里面都可以用局部修正的方法来加以精细调节。ChatGPT也提供了这个功能,但是隐藏得比较深。至少到目前,在电脑客户端和网页版里还没有这个功能,必须要去手机版客户端打开生成的图片,在下方的菜单栏里有一个“Select”选项。我们可以点击这个按钮来给图片加上遮罩。加入遮罩之后,再prompt里继续说“修正Keyboard的拼写”,它就会只改这一个部分,而保留图像的其他部分不变。
这对模型的可控性而言是一个巨大的提升。但是,它也有一个小坑。和Stable Diffusion或者MidJourney之类的系统通过硬性的计算机程序来控制遮罩不同,GPT的这种遮罩似乎还是通过LLM来实现的。因此,在遮罩之外,你可能还是会看见一些微小的变化,但大多数时候这无伤大雅。
这对我们的工作流带来了相当大的改变。现在我们可以不用期待模型一次把所有的事情做对,而是可以一步一步逐步迭代,先确定框架,再改动部分,让我们可以稳扎稳打,逐步精细迭代。
让AI当你的合伙人
第三个技巧是要善用GPT的文生文功能和它进行brainstorm。这和第一个技巧有一定的共同之处,本质上都是在尽可能减少提示词中不明确的地方。只是第一个技巧用的是图片,而这个技巧用的则是更详尽的文字。我们在手工打字的过程中,因为懒或者想不到AI的脑洞,很多时候打出来的提示词是有歧义的。但如果你咨询一下GPT的意见,往往它可以很好地帮你补全这些漏洞,甚至给你一些更好的建议。
比如说,我想把“Dunning Kruger Curve”给可视化出来。网上大多数对GPT的演示和我一开始的尝试都是把这个曲线的内容画在黑板上,旁边加入一些动画角色,让它看起来不那么死板。

这种方法确实比单纯在PPT里放一个XY坐标要好不少,但本质上它并没有改变曲线的内容,只是让它的形式变得更容易接受。更好的方式应该是把这些视觉元素给融入到曲线本体里,让这个曲线不再是冷冰冰的坐标轴,而是和视觉上的角色紧密交融,提供故事性,让大家更容易理解这个曲线的深层含义。但一方面做这样的创意门槛很高,另外一方面也要打很多字。所以我就问了一下GPT可以怎么去设计这样的可视化。GPT给出了非常详尽的回答。接着,我再给了它我原创的一个角色鸭哥的人设和例子,它就输出了一个非常生动的可视化图片。我相信这个图片用到幻灯片里比上面黑板的图片又要好一个档次。
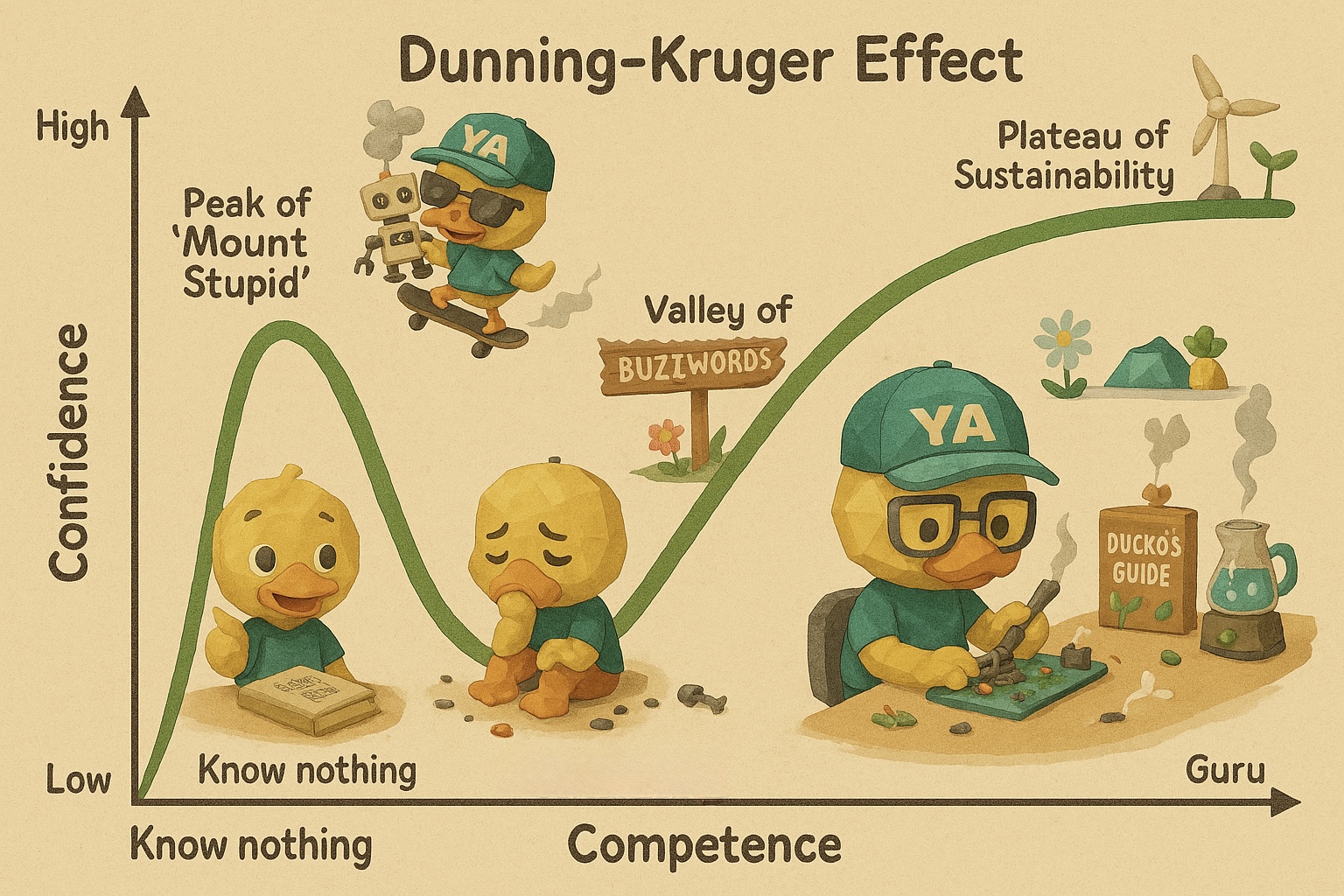
用文档管理打造AI资产库
而这又自然地引出了最后一个技巧:文档管理(Document Management)。在之前我们讨论编程的时候就已经多次提到过这个概念。要想做AI Native Development,不论是文本的程序开发,还是视觉的内容开发,我们都需要注意积累一个系统性的、可以复用的文档。这样才可以在它的基础上进一步深化和发展。
在这个例子里,我们可以通过文档管理来让生成的图片在视觉元素和风格上实现高度统一。比如,因为版权或者公司品牌等等问题,我们不能使用小羊肖恩之类的动画角色,而需要开发一个有自己风格的原创角色和视觉风格。对于这种情况,我们可以首先应用与GPT brainstorm的技巧,把我们想实现的效果跟它说,然后让它生成我们需要的人设和视觉设计。如下图所示。

在这个基础上,我们再应用第一个和第二个技巧,让它在生成新图片的时候,把之前生成的人设和示例图片也作为提示词的一部分,给GPT让它基于这两个元素来进行无歧义的图像创作。注意,这里的人设和视觉例子是可以复用并且不断进化的。当我们看到GPT犯了什么错误的时候,我们可以让它再更改这个人设文档,从而在下次生成图片的时候,避免GPT犯同样的错误。这整个过程就是文档管理。而利用这个原则,我们可以轻松地生成统一的视觉风格,并且把它用到我们的演示文稿中去。一方面让观点变得更加美观、易于接受;另外一方面也方便打造我们个人或者公司的品牌,形成一个AI资产库。


为什么你的Prompt技巧总是过时?
在GPT文生图模型发布之后,网上有一种声音:以前我用Stable Diffusion和ComfyUI的经验都用不上了,相关的Startup也要死一大堆。但从上面的经验出发,我觉得大可不必如此悲观。
如果我们在使用SD等开源模型的过程中,只是机械记忆:人有三条腿的时候就要加negative tag,加参考图像,文本不对就要局部遮罩修正的话,确实有这样的问题。因为这些做法只是对模型特定缺陷的临时修补。当一个新模型出现的时候,它会克服一些旧模型的问题。这些解决方案本身确实就丧失价值了。
但从更深层的角度看,这些修补的深层原理还是可以迁移到新模型上的。比如我们在上面就用了局部遮罩和参考图像的技巧解决了GPT的问题。实际上正因为我有用SD的经验,才能这么快就掌握GPT的高阶技巧。这里的关键在于,我们在知道SD的解决方法以后,有没有多问几句为什么。为什么有些模型会出现六根手指?为什么加了一个局部遮罩就能提升可控性?为什么提供一张参考图片会减少歧义?模型到底是如何解析文字信息并映射到画面的?这些问题的答案往往指向更普适的机制:用户描述不精确造成的歧义;模型生成过程中对空间、文字位置、概念语义的细节把握等等。这类认知并不会随着具体模型而马上过时,而是能迁移到下一个更先进的模型上。换言之,那些表面上针对旧模型的“技巧”之所以能过时,只是因为它们是拿一把特殊螺丝刀解特定的螺丝,但如果你理解了为什么螺丝要这样拧、螺纹是怎么形成的,那么换一把新型号的螺丝刀,一样可以快速上手。
所以问题的关键在,与其把自己放在纯粹User的位置,被动等待模型升级、学习新一套Prompt,不如去做一个Builder,去反复追问为什么,并且在每次解决问题后都留下可以复用的经验与文档。一旦形成了这种主动思考和迭代的习惯,我们就不会被模型的大步进化牵着鼻子走,疲于奔命。而可以带着既有的深层原理去探索新功能,主动掌握甚至预测模型未来的更新。这才是Future-Proof的真正含义:不把赌注押在任何一款具体的工具上,而是让自己拥有足够的洞察与方法论,去面对潜在的技术更新迭代。而这也是我们的课程"From Users to Builders: Transform Yourself for the Age of AI"所能教会你的核心[在线授课版][离线视频版]。