OpenClaw在2026年1月底爆火。公众号铺天盖地都在介绍怎么配置,云服务厂商都速度上线了一键部署,生怕错过这波热度。与此同时,各种行为艺术又满天飞:ClawdBot、MoltBot、OpenClaw,一周内改了三次名;结果改名的时候账号还被抢注,被一个叫$CLAWD的代币诈骗了1600万美元。与此同时,安全漏洞也层出不穷:有12%的第三方skills含恶意代码,有不少人把控制台裸露在公网上没设密码。一时间让人感觉整个领域全是相互矛盾的噪音,无所适从:这东西到底要不要装?不装会错过什么?装了有什么风险?这到底是下一个生产力革命还是又一个两周就过气的玩具?
这篇文章就想从更高层的角度抽丝剥茧:OpenClaw到底做对了什么,为什么是它火,以及这跟我们有什么关系。
为什么会火的暴论
我有一个暴论:OpenClaw火的原因,和去年这个时候DeepSeek火的原因,是高度类似的。
DeepSeek流行的时候,当时国内大家用的AI主要是纯聊天,没有搜索功能也经常信口瞎编。ChatGPT和Claude虽然有了思考和搜索功能,智能强很多,但国内用不了。DeepSeek引入了推理功能和搜索功能以后,第一次让大家体验到了会搜索懂思考的AI,带来了一种震撼:哇,AI还能这么有用,就爆火了。换言之,这个火不是因为技术上比竞争对手更好,事实上DeepSeek在纯模型能力上并没有碾压同时代的GPT-4o或者Claude 3.5。而是因为把一小撮人享受/习惯的事情,一下子推广到另一群更大的用户群面前,这才火起来。
OpenClaw也是一样。2026年初Agentic AI领域其实有一个断层:ChatGPT这种产品虽然流行,但相比Cursor/Claude Code/Codex这种有本地权限的编程Agentic AI,整体能力还是落后了至少一代(具体为什么后面有解释)。但Cursor这种工具非常小众,基本上只有程序员在用。大家用的还是ChatGPT这种消费级产品,就觉得AI这两年没啥进步,能力很有限。然后OpenClaw第一次把Cursor这种能本地编程的Agent和WhatsApp/Slack/飞书这种流行通信软件接起来了,让非技术人员这种更广大的用户群第一次接触到了能读写文件,能执行命令,有记忆能持续迭代的Agentic AI,就爆火了。换言之,这个火不是说OpenClaw在技术上做到了什么新的事情,而是因为把一小撮人享受/习惯的事情,一下子推广到另一群更大的非技术用户群面前,这才火起来。
但我说这些不是为了得出结论说OpenClaw、DeepSeek是花架子,没必要学。恰恰相反,DeepSeek从历史的角度提供了很多启发。比如DeepSeek火了以后,真正从中受益的是哪些人?我的观察是,有没有跟风第一时间玩上DeepSeek本身并不重要。很多人玩了一段时间就退烧了。真正理解了DeepSeek为什么火,把搜索和推理这两个关键因素整合到了自己工作流里的人,才是真正受益的人。类似的,OpenClaw火了以后,我们确实可以去跟风安装使用、体验一下,但这件事情本身并不会让我们一下就脱胎换骨生产力倍增了。因为这种现象级产品能爆火的重要前提是它是面向最广泛的用户设计的,因此设计决策上有很多妥协,直接用往往效率并不是最优。更关键的是要去理解它背后的设计哲学,分析它爆火的原因,从中吸取经验教训,改进自己的工作流。
毕竟,工具会过气,对工具本质的理解不会。把可迁移的认知抽出来,融入自己的工作流,这才是内行的做法。
聊天界面:流行的基础,也是天花板
在具体分析OpenClaw的牛逼之处之前,我想先带大家看一个具体的例子,来解释“OpenClaw是面向最广泛的用户设计的”这句话到底是什么意思,以及有什么影响。
前面我们提到OpenClaw火起来非常关键的一点是,它选用了大家天天都用的聊天软件作为交互入口,而不是像Cursor一样让你在电脑上多装一个软件。这样可以复用现有的使用习惯和渠道,让用这个工具的心智负担特别低。你没事反正都要用Slack/飞书,正好就看到了OpenClaw就会想着用用。另一方面,因为大家本身就非常熟悉这些软件的使用,所以它把学习成本也几乎压到了零。不需要装IDE,不需要学编程的术语概念,拿起手机就能用,这是它能出圈的基础。
但如果你用过Cursor这种Agentic AI编程软件的话,就会发现Slack这种聊天窗口对AI来说是个相当受限的交互方式。
第一是它要求对话是线性的。像Slack和微信这样的聊天窗口主要就是一条条消息往下排。但是深度的知识工作往往不是线性的。比如你需要引用另外一个thread的内容,需要把两个方向的探索merge在一起,需要在某个会话中fork出去。这些在桌面环境里比如Cursor和OpenCode里面都有专门的UI可以实现,但是在聊天窗口里面做就特别别扭。
第二个问题是信息密度。如果只是做玩具性质的调研和开发,聊天窗口是没有问题的。但凡要做更复杂一点的分析和思考,它的信息密度就捉襟见肘了。比如图文混排的分析报告、复杂的表格、带格式的长文,这些在聊天里面看还都蛮痛苦的。同时不同平台对Markdown的支持也参差不齐,体验很不稳定。
第三个问题出在过程的可观测性上。尤其是对要分好几步才能完成的任务,我把执行权交给AI以后,很自然地会想关心它到底在干啥。比如它是在稳步推进,还是在钻牛角尖鬼打墙?它调用了什么工具,改了哪些文件?这些在Cursor等等工具里会有自然的呈现,但是聊天窗口我们只能看见一条“对方正在打字”或者一个emoji表示正在处理。尤其是比较复杂的任务,OpenClaw需要等蛮久才能等到一条消息告诉我们搞定了还是中间挂了。
但是我说这么多不是想说OpenClaw设计不好,而是想说这里面有个很明显的妥协(trade-off)。你要想把工具做得容易上手、面向最大的用户群,就必须用聊天工具这些人人都已经在用的工具作为载体。但这同时立刻又带来了对话形式、信息密度等等弊端。反之亦然。在这个从“易用但是拧巴”到“原生但是小众”的连续的trade-off空间里,OpenClaw选择了极致的易用性。这是它能爆火的基础。但我们也要清醒地认识到这种设计决策所带来的限制。在融合进自己工作流的时候,不是无脑地采用OpenClaw的所有设计,而是应该因地制宜,根据自己的需求来在这个trade-off轴线上找到属于自己的甜点区。
理解了这个trade-off,后面的分析就容易理解了。
界面之外的流行要素
聊天界面是OpenClaw流行的基础,但只是最浅显的一点。真正让用户觉得这个AI真的智能,好用,懂我的,是它背后的三个设计决策。
第一个是统一的入口和上下文。对比一下Cursor就很清楚。在Cursor里每个项目的上下文是隔离的——打开项目A,AI只知道项目A的事;切到项目B,之前关于项目A的对话就全没了。Claude Code、OpenCode也一样,每次启动都绑定一个工作目录。但OpenClaw则完全相反。它默认把所有对话的上下文混在一个池子里。你上午在Telegram里让它帮你整理邮件,下午在Slack里让它写个报告,晚上在WhatsApp里让它安排明天的日程——它全都记得。给人的感觉就是它特别聪明,好像真的认识你。
但光把上下文混在一起是没用的,因为上下文窗口很快就会满了。这就牵扯到了它的第二个关键设计,持久化记忆。OpenClaw对记忆的处理非常巧妙,很值得学习。从大的原理上,它和Manus一样用的是基于文件的记忆系统。比如它维护了一个SOUL.md,定义AI的核心人格和行为准则;USER.md保存了对用户的画像,MEMORY.md存长期记忆,再加上每日的原始日志等等。
这里面比较巧妙的是它有个自我维护机制:AI会在每隔一段时间(heartbeat)自动review最近的原始日志,把有价值的信息提炼到MEMORY.md里,顺便清理过时的条目。整个过程不需要用户干预。这个自我维护机制就把记忆给分层了,原始日志是短期记忆,每天的MEMORY.md是中期记忆,提炼出来的个性和喜好是长期记忆。对用户来说,体验一下就从“每次重开都要重新交代一遍"变成了"它好像在成长",这个感知差异是非常大的。
第三个设计是丰富的Skills。这个意义要远超节省那么一点用户的时间。工具数量带来的好处不是线性的——6个工具比4个工具的能力提升,远大于4个相对2个。这是因为工具之间可以组合。接Slack能管下达指令,状态汇报,接图像生成能画图,接PPT服务能出稿,接deep research能调研。这些凑在一起,就可以组合进化出很多完整的业务能力和应用场景。
这三个设计之间也不是简单的加法,而是互相促进的。
记忆加上统一的上下文池,会带来数据复利。因为有持久化记忆,对话可以跨会话积累;因为有统一入口,所有来源的数据汇进同一个记忆池。你在Slack里讨论的工作内容、在Telegram里安排的日程、在WhatsApp里的个人对话,全部混在一起,形成了对你越来越完整的理解,以后完成任务也会越来越贴心。
记忆加上skills,带来了自我进化的能力。今天学到的用法明天还在,能力会累积;AI自己能写新的skill并且记住它的存在和用法,这就进入了正循环。这里面特别值得一提的是coding能力。因为OpenClaw自己能写代码,所以遇到没有现成skill可用的时候,它就可以当场造一个。这个新skill会被保存下来,下次遇到类似场景直接复用。这就形成了自我进化的闭环。
而这些能力和界面的易用性加在一起,又带来了使用频率。入口越顺滑,调用越频繁,飞轮越转越快,能力越来越强。
总之,OpenClaw是一个相当厉害的产品。它的各种决策,不论是技术的(入口、记忆、工具)还是非技术的(界面),都在为同一个飞轮服务,让普通人第一次摸到了Agentic AI的完整形态。
限制和trade-off
前面说了它为什么牛,下面我要开始吐槽了。但我想先解释一下,下面介绍的这些限制不是说OpenClaw疏忽了没做好,而是前面说的那个trade-off的直接后果——为了爆款好用必须付出的代价。
界面的限制前面已经说过了:线性、低信息密度、低可观测性。在深度使用时这些很快会成为瓶颈,这里不再赘述。
更深层的问题在记忆上。OpenClaw的记忆系统对小白很友好。你不用管,它自己就会打理和进化。但对想把知识沉淀成资产的人来说,这反而是一个障碍。
举个栗子,比如我们做完一次调研,产出了一份5000字的长文或者一份PRD。在Cursor/文件系统里它就是一个文件:docs/research.md,想引用就@,想升级就开新版本,想对比就diff。但在OpenClaw里,这份东西像是人类记忆一样,说不定什么时候就会被自动摘要、自动重写,甚至整个被删除了(遗忘),整个过程完全不可控。你很难跟它说清楚:以后就以这份文档为准,遇到相关问题必须引用它,不要给我压缩成三行。总之就是,知识没办法显式管理。
更让人头疼的是整个更新过程也是一个黑盒。MEMORY.md里存什么、怎么组织、什么时候清理,主要是AI在heartbeat期间自动做的。你看到的是结果,很难看到原因:它这次改了哪些条目,为什么删掉这一条,为什么把两个不相关的东西合并在一起。出了问题也很难定位根源,因而很难改进。
OpenClaw记忆系统的设计带来的另一个问题是跨场景的信息干扰。统一记忆当然带来懂我的感觉,但也意味着信息很容易跨项目污染:A项目的偏好、甚至某个临时决定,可能会莫名其妙影响到B项目。对小白来说它好像什么都记得,但对真的想干活的进阶用户来说更像是“我去怎么又被它带偏了"。
Skills的安全隐患又是另一类问题。ClawHub上的上千个技能中,安全审计发现有上百个包含恶意代码——加密货币盗窃、反向shell后门、凭证窃取都有。Simon Willison提过一个致命三角的概念:一个AI系统同时具备访问私有数据、暴露于不可信环境、能够对外通信这三个能力时,风险是指数级放大的。OpenClaw三个全中🤡。这就形成了一个奇特的悖论。你要想用的爽,就必须给他很多工具和权限。但这又会带来安全问题,所以就要把权限收得很紧。但权限收紧了就又变成类似Manus那样的云端Agent服务了,没了本地Agent的爽。安全和好用,似乎成了一对矛盾。
So What?
讲到这里,自然会有人问:分析了一堆,然后呢?这跟我有什么关系呢?
回答是:可以用这些认知,在已有的工具上搭一套比OpenClaw更顺手的东西。我自己就是这么干的,效果比直接用OpenClaw好很多。下面讲几个关键决策。
复用Agentic Loop,而不是自己造
我们做的第一个决策,也是最重要的一个,是不自己从头实现一套Agentic AI系统,而是复用OpenCode这样的开源CLI编程工具作为基础。
这个决策背后有一个更深层的判断。做一个能用的Agentic Loop——也就是调API、解析工具调用、执行工具、把结果返回给AI、请求下一次回答这个循环——说起来简单,但要做到能支撑真实使用的水平,有很多细节:文件系统的读写,文件内容的新增删除替换,沙箱环境,权限管理……每个都是坑。这些东西写起来繁杂、充满陷阱,而且和我们最终想创造的价值没有多少关系。我之前的一篇文章里详细讨论过这个问题——核心观点是,Agentic Loop是体力活,应该外包;真正值得花精力的是Agentic Architecture,也就是怎么把业务逻辑注入AI系统让它直接创造价值。
而OpenCode、Claude Code这类工具,恰恰就是一个特别好的外包。它们已经把Agentic Loop做得非常成熟了——能读写文件、能跑命令、能持续迭代,而且还在飞速进化中。用它们做基石,等于是白嫖了整个agentic编程工具链,可以把自己的开发成本降到最低。而且选OpenCode还有一些额外的好处:它完全开源可以魔改,支持并行的subagent(Cursor和Codex到现在都还没有),还支持多种coding plan——比如我自己用的是GLM的coding plan,也可以直接用OpenAI的Codex plan,不用像直接调API那么烧钱。
文件即记忆:继承和发展OpenClaw的哲学
第二个决策是在记忆体系上。OpenCode/Claude Code这类工具天生就有磁盘即记忆的思想——毕竟它们作为编程工具处理的基础单元就是文件。当我们又有基于磁盘的记忆,又有对文件直接的操纵权和透明度的时候,就解决了前面分析中OpenClaw记忆系统的问题。想沉淀资产就写文件,想强制AI遵守某些规则就写AGENTS.md,想管理记忆结构就直接编辑Markdown。前面说的那些知识没法显式管理、更新过程是黑盒的问题,用OpenCode的细粒度控制和文件系统天然就解决了。
但光有文件系统还不够,我们还把OpenClaw那套persona自我进化的机制移植了过来。具体来说,我们把记忆分成了两层:project-level的记忆(每个项目自己的上下文、决策记录、技术方案)和persona-level的记忆(用户画像、行为偏好、沟通风格)。然后在AGENTS.md里加入persona维护的workflow,让AI在session结束时自动review对话、更新MEMORY.md和USER.md。同样的自我进化,但跑在完全可控的文件系统上,还能用Git做版本管理。
至于统一上下文的问题,我们用了一个很简单粗暴的方案:Mono Repo。把不同项目放在同一个repo的不同文件夹下,AI天然就可以跨项目访问所有上下文。想隔离就隔离,想共享就共享,想merge两个方向的探索就直接@,想fork出去就复制文件——全都是文件系统和OpenCode的原生操作,比OpenClaw在聊天窗口里拧巴地做这些事情自然太多了。
Skills和安全
Skills方面,OpenCode生态有大量MCP server和Skills可以接入——日历、邮件、浏览器、搜索等等——功能覆盖和ClawHub大差不差。安全性上,我们的做法是不直接安装第三方skill,而是让AI先审查源码、理解逻辑,然后重写一个干净版本。在AI辅助编程的今天这个过程通常只要几分钟,但可以极大降低供应链攻击的风险。
最后一公里:移动端
前面三个决策解决了底座、记忆和工具的问题,但还差一个关键的东西:入口。OpenClaw火的一个重要原因是你不用坐在电脑前面。但现有的编程工具在这方面确实拉胯——VSCode有个Code Server可以远程访问,但对iPad非常不友好;OpenCode有个Web Client,但说实话只是解决了有和无的问题,非常难用;Cursor的Web Client高度绑定Github;Claude Code则完全没有Web Client。
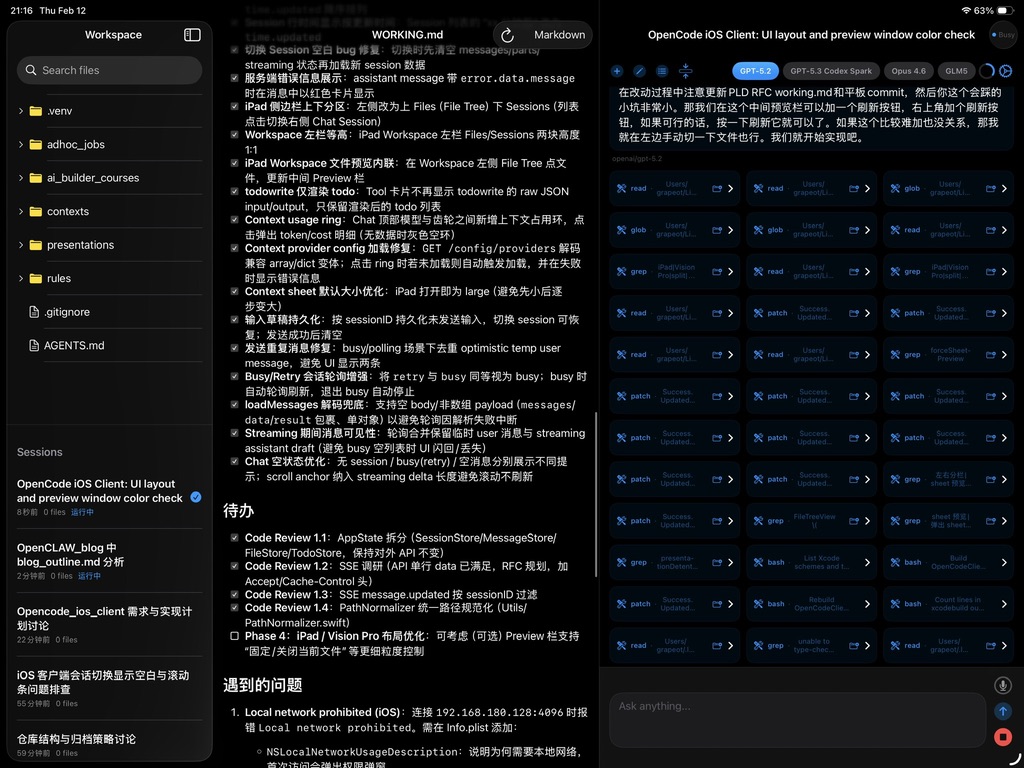
为了解决这个问题,我们做了一个原生的iOS App作为OpenCode的远程客户端。注意这个App不是把聊天窗口搬到手机上——它是一个真正为移动端设计的工作界面:能看到AI的实时工作进度,每一步工具调用、每一个文件操作;能切换模型做A/B测试;能浏览Markdown文件和审查更改;支持语音输入;支持基于HTTPS或者SSH隧道的公网访问;iPad上还有三栏分屏。
这个客户端已经在github上开源了。欢迎大家也来体验。未来可能会加入TestFlight。效果是吃灰很久的iPad重新变成了生产力工具,在沙发上指挥AI干活的体验比OpenClaw的聊天窗口爽得多。外出吃饭的时候接到oncall,也可以直接给AI小弟布置任务,当场就搞清楚了原因。而且全程都有对AI完全的掌控,知道它不会出幺蛾子,也不会把你的信息po到Moltbook上。
总结
回到开头的暴论。OpenClaw和DeepSeek的火,本质上是同一件事:把一小撮人已经在享受的能力,第一次推到了更广泛的人群面前。DeepSeek让大家第一次用上了会搜索懂推理的AI,OpenClaw让大家第一次摸到了能读写文件、有记忆、会自我进化的Agentic AI。
但也正因为要面向最广大的普通用户,这类产品必然在设计上做大量妥协。DeepSeek如此,OpenClaw也如此。聊天界面带来了易用性但牺牲了表达力,统一记忆带来了懂我的感觉但牺牲了可控性,开放的Skills生态带来了能力但引入了安全风险。
对于已经在用Cursor/Claude Code/OpenCode的人来说,更值得做的不是无脑跟风装一个OpenClaw,而是理解它为什么火——统一入口、持久化记忆、工具生态,以及它们之间的飞轮——然后把这些认知融入自己已有的工具链里,扬长避短。我们自己就是这么干的,效果确实比直接用OpenClaw好很多。
毕竟,工具会过气,对工具本质的理解不会。