Why?
It often requires a lot of computational resources to do machine learning / computer vision research, like extracting features from a lot of images, and training large-scale or many classifiers. Therefore people use more than one machines to do the task. The procedures are often like, copy executable/data files to all the machines, configure environments, manually divide the tasks, actually run the commands, and collect the results. In addition to the complicated workflow, another practical problem is where to get the machines. Maintaining your own cluster is definitely an option, an extremely expensive and time-consuming option. Renting from AWS, especially using spot instances, is a much cheaper and more practical alternative.
But a lot of factors prevent them to be really useful (I assume you already know how spot instances work):
- Spot instances don't have persistent storage, which means whatever you have on the hard disk may lost in the next minute. How to deal with this?
- This property of spot instances also makes system configuration a problem -- how do you easily make a blank system usable?
- How to efficiently copy bulk of data to AWS?
- Manual task division and command execution doesn't sound right. How to make it easier and smarter (and faster)?
After quite a few months, I gradually accumulate a tool chain to handle all of these problems.
What will you get?
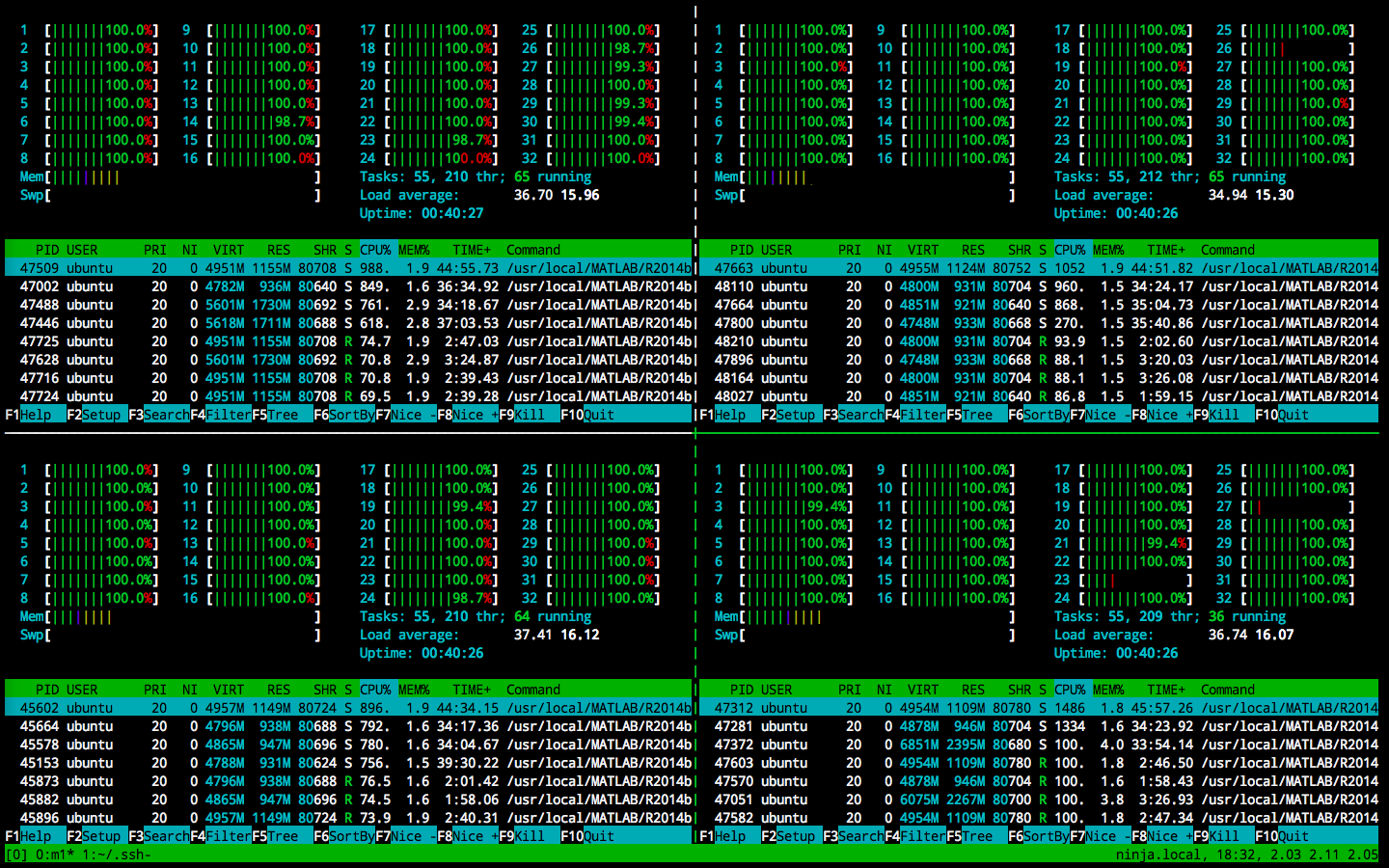
Here is an example of a 128-core 240GB cluster. It requires ~10 minutes to build from scratch (or ~1 minute to build from AMI image), and costs about 1 dollar per hour. Like any AWS instances, the instances themselves cost nothing if you don't use them (by shutting them down). All your data will be on your hard disk and the loss due to spot request failure will be minimized. The best thing is, task submission is fairly simple -- one single line of bash command will do the job, like
cat cluster.sh | parallel --sshlogin 8/m1 --sshlogin 8/m2 --sshlogin 8/m3 --sshlogin 8/m4 bash -c '{}'
It will automatically distribute every line of cluster.sh to the four nodes, and display all the stdouts on your screen.
Whenever a node has less than 8 tasks running, the script will automatically dispatch one to it.
How? (TL; DR)
- Use automated script to do fast system configuration.
- Use
sshfsto do selective file transfer with compression, including training data transfer and result collection. - Use GNU
parallelto do job submission. - AMI can also be used to further expedite virtual machine initialization
How?
- Create spot instances on AWS.
- On each machine,
git clone http://github.com/grapeot/debianinitand executesetup-ubuntu.shto initialize the system. Note the script is personalized for me withpythonandvimsupport. Folk it to add your own stuffs. - That's it for configuration. To submit jobs, use
parallel. Let's look at this example:
cat cluster.sh | parallel --sshlogin 8/m1 --sshlogin 8/m2 --sshlogin 8/m3 --sshlogin 8/m4 bash -c '{}'
(Thanks to OleTange's comments, it can be simplified as cat cluster.sh | parallel -S8/m{1..4} -c '{}')
We already explained what it means, and here are more details.
For switches like --sshlogin 8/m1, --sshlogin means to send the task to remote machines.
8/m1 tells parallel to send it to a ssh host named m1, which you can configure in ~/.ssh/config, and maintain at most 8 tasks on that host.
bash -c '{}' is the actual command to execute on the remote machine, with {} as the placeholder for each line from stdin.
parallel is much more flexible than this, and I'd leave the exploration of more switches and usage to you. :)