智谱在 2026 年 5 月 22 日开放了 GLM-5.1 高速版 API,输出速度 400 tokens/s。这个数字放在上下文里看:人类阅读速度通常在每秒 3 到 5 个 token,也就是说这个 API 的输出速度是你阅读速度的 80 倍以上。体感上,量子位的实测描述很准确:模型思考十几秒后,代码”喷出来”。
但 400 tokens/s 这个数字本身不是重点。重点是它揭示了一个正在发生的转变:AI API 的竞争轴,正在从”模型有多聪明”转向”聪明且有多快”。在 Agent、实时编程、语音交互这些场景里,用户等待的不是单次回复,而是一个持续流动的交互循环。每一次工具调用、每一次代码补全、每一次 reasoning step,都在压缩可容忍的延迟预算。
这篇文章想讲清楚两件事。第一,让 GLM-5.1 达到这个速度的不是”优化得更快”,而是”换了一种执行方式”。TileRT 推理引擎从执行模型层面做了重构。第二,为什么这个转变对整个 AI API 生态有结构性的影响。
TensorFlow 的静态图模式和 TensorRT 的编译优化,核心思路都是把计算图提前编译好,运行时就快了。编译期可以预先规划内存分配、融合相邻算子、消除冗余计算。
但这里有一个容易被忽略的前提:编译优化消除的主要是启动成本,而不是步骤边界。
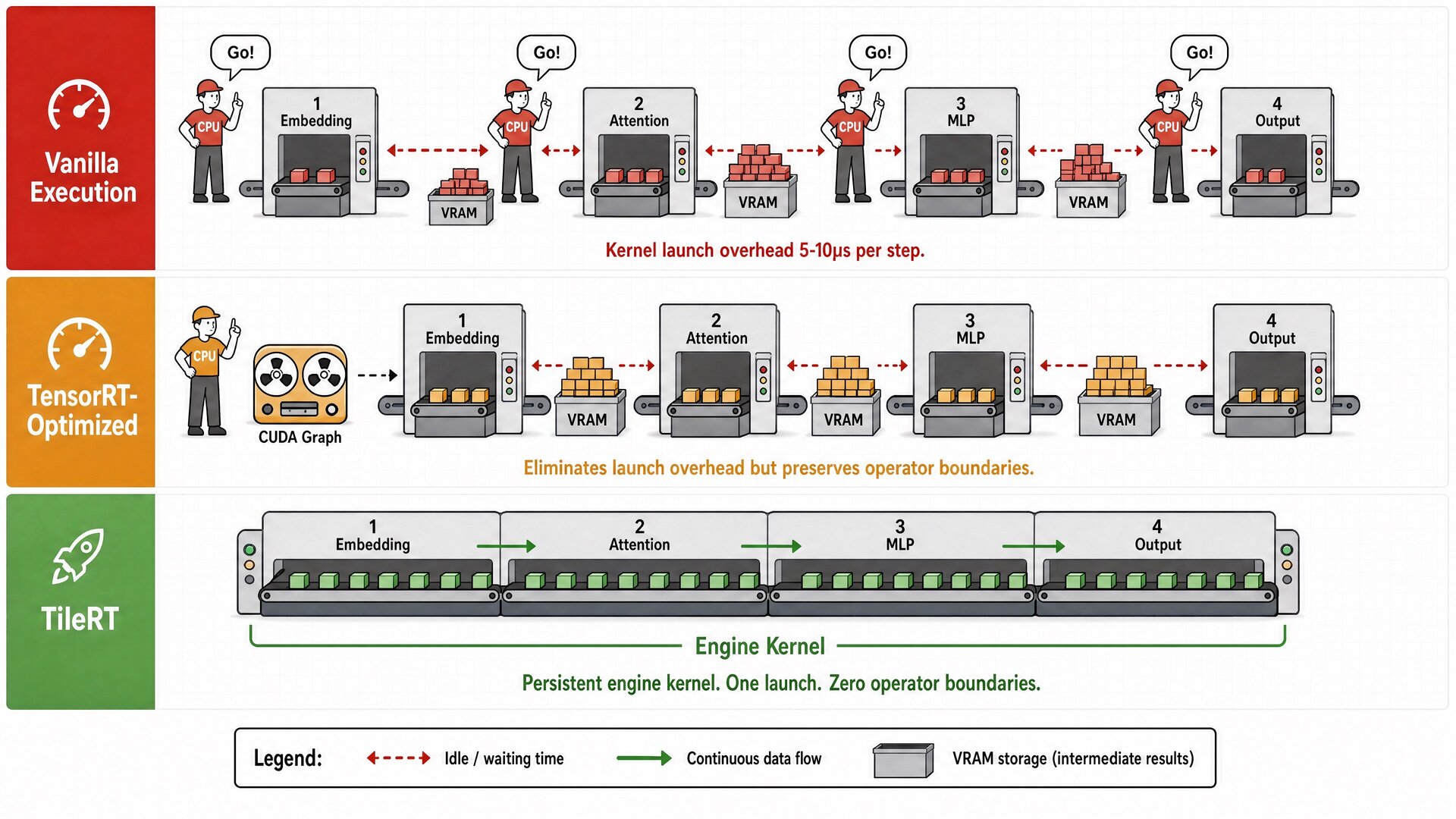
想象一个工厂,每个工位负责一道工序,先切料,再打磨,再组装。
传统框架的执行方式相当于:工头喊一声”开工”,第一个工位开始干活。干完一整批产品之后,所有半成品入库。工头再喊一声,第二个工位从仓库里搬出半成品继续干。TensorRT 这类编译优化的作用,相当于工头提前把指令录好,到时候自动播放,省掉了喊话的时间。但它没有改变一个根本事实:产品仍然要在一个工位做完一整批,入库,出库,再进下一个工位。
当批量很大时,这套模式没有问题。每个工位要忙很久,几十毫秒甚至上百毫秒。工位之间的转移成本,入库出库那几微秒,相比之下可以忽略不计。
但当批量被压缩到接近 1,这正是实时交互场景的常态,每次只生成一个 token,事情就变了。每个工位的实际加工时间骤降到微秒级,但工位之间转移的成本不变。产品在每个工位上只花了 2 微秒,但在工位之间转移花了 5 到 10 微秒。一半以上的时间不是在加工产品,而是在等下一个工位准备好。
这就是 TileRT 团队在他们的技术博客里描述的发现:GPU utilization 很高,理论算力也不低,但 token 生成速度就是上不去。因为算力不是不够,是算力被困在工位与工位之间的空隙里了。
一台 8×H200 NVL 服务器,按理论带宽估算,decode 上限接近 1000 tokens/s。但真实系统里往往只有几十 tokens/s。差了一个数量级。不是某个工位太慢,而是整个工厂有一半时间在等人喊开工。
核心思路:把整个工厂从”批处理车间”改造成”连续流水线”。产品不再是一个批次做完才往下一个工位推,而是一个零件一个零件地往下流。上一个工位做完一个零件,直接递到下一个工位,不需要入库出库。工头在整个生产周期里只喊一次”开工”,之后所有的调度、同步、传递都在车间内部自己完成。
TileRT 在编译期,也就是模型还没开始跑的时候,就把整个模型的计算流程提前编排好,生成一个持续运行的总装管线。到了运行期,这条管线常驻在 GPU 上不退出,数据持续流过所有计算步骤,中间结果不再反复写回显存再读出来。
TensorRT 的编译优化是在工位层面做的:让每个工位更快,把相邻工位合并。但工位与工位之间的隔离墙还在。TileRT 的编译是在工厂层面做的:它不只是优化每个计算步骤,而是把整个计算流程当作一个整体来编排,消除了步骤之间的隔离。
当这条连续流水线跑起来之后,三件事情可以同时发生。
第一,不同计算步骤的零件可以交叉推进。attention 的一部分结果算出来,MLP 就可以立刻开始处理,不用等 attention 全部完成。
第二,数据搬运和计算可以重叠。搬运下一批数据的同时,当前这批还在算。
第三,在多 GPU 场景下,不同 GPU 不再做同样的工作然后停下来同步。它们根据各自的计算密度承担不同职责,有的专门做索引查找,有的专门做密集计算。就像流水线上的不同工位,各司其职,不用所有人停下来对齐。
这三件事合在一起的效果:GPU 不再表现得像不断启动、停止、启动、停止,而更像一台持续运转的发动机。
在单卡 B200 上,TileRT 对一个 MoE 模型的端到端解码速度是 vLLM 的 1.48 倍(batch size=1)。更值得注意的是 warmup 开销:vLLM 需要 123 秒、SGLang 需要 583 秒来预热启动,因为它们要在运行期反复做 JIT 编译和 CUDA Graph capture。TileRT 只需要 35 秒,它的编排在离线就完成了,运行期直接加载。这在需要频繁扩缩容的生产环境里有直接的运维价值。
关于 TileRT 的技术细节,arXiv 上有一篇 Event Tensor 论文给出了完整的学术表述。开源代码在 github.com/tile-ai/TileRT,不过需要说明的是,目前仓库只暴露了 Python 层的模型定义,核心的 kernel 编译和调度引擎尚未完全开源。
400 tokens/s 不是 TileRT 单独做到的。GLM-5.1 的模型架构在设计时就考虑到了与推理引擎的配合。
第一,稀疏激活。GLM-5.1 是一个 744B 总参数、但每 token 只激活 40B 参数的 MoE 模型(详见 GLM-5 技术报告)。这就好比工厂只处理当前订单需要的零件,不用把所有库存都翻一遍。单步计算量天然就小,给了推理引擎在计算密度和并发度之间腾挪的空间。
第二,一次预测多个 token(MTP)。传统的自回归生成是一个一个 token 往外蹦。每蹦一个,就得跑一遍整个模型。GLM-5 的做法是训练模型同时预测接下来的 2 到 3 个 token,然后主模型快速验证哪些可以接受。实测中,平均每步能产出 2.76 个 token(DeepSeek-V3.2 是 2.55)。在 TileRT 的连续流水线模式下,这意味着流水线跑一圈能产出更多产品,每圈的固定成本被更充分地摊薄。
第三,稀疏注意力(DSA)。在长上下文场景下,传统注意力需要对所有 token 两两计算相关性,计算量随上下文长度平方增长。DSA 的做法是让模型自己判断哪些 token 重要、只对重要的做注意力计算,把计算量砍掉 1.5 到 2 倍。省下来的计算带宽被 TileRT 的管线用来覆盖数据搬运和通信的时间。
稀疏激活、多 token 预测、稀疏注意力,这三项是模型层面的贡献。但单独拎出任何一项都达不到 400 tokens/s。它们和 TileRT 形成的是一个正反馈:流水线模式让多 token 预测的验证步骤不再引入额外延迟;MoE 的动态路由在 GPU 内部完成负载均衡,不需要 CPU 端反复介入调度;稀疏注意力省下来的计算带宽正好用来掩盖通信延迟。引擎和模型互相为对方的设计选择提供了加速空间。
把 GLM-5.1 放回行业坐标系里看。
当前的 AI API 速度大致分为三个梯队。
GLM-5.1 的 400 tok/s 如果属实并且来自通用 API,意味着它在 frontier 智能水平上达到了接近 Mercury 2 的量级,显著领先于当前所有主流 API 的快速模式。但需要注意:这个数字目前缺乏 Artificial Analysis 等独立 benchmark 的验证,量子位的实测也明确表示需要更多条件下的持续验证。
各家做快速模式的技术路线本质上是四类。Anthropic 的 Fast Mode 用同一个模型,通过调整推理配置实现 2.5 倍加速,代价是价格乘以 6。模型质量完全不变,但商业模式从”卖智能”转向”卖智能×速度”。Google 的 Gemini Flash/Pro 分层是训不同大小的模型来覆盖速度-质量谱系。Fireworks 等第三方 provider 走推理优化路线,同一模型在不同 provider 上速度差 5 到 6 倍,靠 speculative decoding、量化、kernel 优化。智谱的 TileRT 路线和这三个都不一样:不是改配置、不是训小模型、也不是优化现有框架,而是从执行模型层面做重构。
为什么这四类路线的差异重要?因为它指向了两个不同的竞争逻辑。
“质量竞争”比谁的模型在 benchmark 上得分更高。GLM-5.1 在 SWE-bench Pro 上 58.4% 已经超过了 GPT-5.4 的 57.7%。但这类竞争的天花板在收窄。前沿模型的智能差距越来越小,benchmark 分数越来越接近。
“质量×速度竞争”的逻辑是:当几个模型都能完成同一个任务,谁能更快完成。编程场景里这个逻辑特别明显。Cursor、Claude Code 的用户体验不取决于模型能写出多精妙的代码,而取决于从发出指令到看到第一段可用的代码需要多久。输出速度从 40 tok/s 提升到 400 tok/s,一个 2000 token 的代码片段从等待 50 秒变成 5 秒。前者你会起身去倒杯水,后者你只是等了一小会儿。
智谱的股价在 5 月 22 日当天盘中涨超 22%,虽然同时叠加了恒生科技指数纳入预期和港股通资格的利好,但 400 tokens/s 是一个有效的市场信号。摩根士丹利预测智谱纳入港股通后可能吸引 439 亿港元(约 56 亿美元)南向资金。智谱 IPO 基石投资约 30 亿港元,南向资金预估值是它的 15 倍。
从行业格局看,推理速度正在成为第二条竞争轴,这个过程和两年前推理成本的竞争轨迹相似。DeepSeek V4 Pro 今天刚宣布把之前 75% 的促销折扣永久化——API 价格变成原来的四分之一。这个动作本身就是成本竞争白热化的信号。当成本低到用户对价格的敏感度下降,速度就成了下一个让人皱眉头的维度。用户不再问”为什么这么贵”,而是问”为什么还在转圈”。
这是一个经典的瓶颈迁移:推理成本曾是主要瓶颈,成本降下来后瓶颈转移到了延迟。当延迟也被压缩,下一个瓶颈可能是什么?可能是推理系统的可靠性、KV cache 的管理效率、多 agent 协同的协调延迟。
对 AI 编程工具来说,这个转变有直接的产品含义。100 tok/s 和 400 tok/s 的差别不是 4 倍的”更快了”,而是从”被动等待 AI 写代码”到”和 AI 一起看着代码流动”的交互模式切换。用户的留存、使用频率和任务完成率在这两种模式下会有数量级的差异。
对智谱来说,选择”速度×质量”而不是继续压价是一条有差异化的路径。DeepSeek 已经把价格压到极低,继续在价格上竞争边际收益有限。而速度上有真实的产品需求缺口:所有做 Agent、做编程工具、做实时交互的公司都在要更快的推理。这可以解释为什么 TileRT 目前只服务企业客户:高频率、低延迟的 enterprise workload 是”速度×质量”策略最有效的试验场。
TileRT 团队在博客里提了一个判断:“Speed itself becomes a scaling law.”
这个判断的逻辑是:在 Test-Time Scaling 的范式下,模型通过更多推理步骤来提升答案质量,推理速度直接影响模型在固定时间内能完成的 reasoning depth。同样给你 10 秒,一个每秒 400 token 的模型能走更多的推理路径、做更多的自我验证,最终答案质量可能因此更高。速度不再是只影响用户体验的锦上添花,而是开始直接影响模型能力的参数。
这个逻辑可以推广。如果 Agent 的执行速度从几分钟压缩到几秒钟,Agent 可以做更多轮次试错、更多环境交互、更多自我修正。AI 编程工具的响应从肉眼可见的延迟变成接近瞬时,人与 AI 的协作会从”我发指令,AI 执行,我检查”变成”我和 AI 一起边想边写”。前者是异步协作,后者是同步协作。两种模式的产品形态、使用场景和用户留存完全不在一个层面。
目前 400 tokens/s 还需要独立 benchmark 验证,TileRT 也没有对全部开发者开放。但在技术路线上,它指向了一个重要的方向:当推理延迟成为核心瓶颈,优化的着力点会从”让每个计算步骤更快”上移到”让整个计算流程不断裂”。编译时静态编排、把整个模型当作一个整体来优化、让 GPU 持续运转而不是频繁启停,这些想法可能会在接下来一两年出现在更多推理引擎的技术路线图里。
推理速度的竞争和推理成本的竞争有一个关键不同:成本有地板,接近电力成本;速度的天花板由硬件物理极限定义,这个天花板还很高。TileRT 博客里那张表:理论上限约 1000 tokens/s,当前生产约 400 tokens/s,还有 2.5 倍空间。这还不算下一代硬件带来的带宽提升。
如果这个方向被持续投入,接下来一两年我们可能会看到 frontier 模型的推理速度普遍突破 200 tok/s,快速模式成为标配而不是单独收费的高级功能。就像当年 GPT-4 级别能力从”需要申请”变成”随手可得”一样。